

Cómo un error de datos le costó millones a la NASA (y qué podemos aprender)

La inteligencia artificial y los modelos predictivos están transformando industrias enteras. Pero detrás de todo modelo exitoso hay una verdad incómoda (que pocos quieren resolver): sin datos de calidad no hay decisiones de calidad. Este principio aplica tanto en proyectos de ciencia de datos como en dashboards o reportes de negocio.

Un caso extremo: cómo un error de datos le costó millones a la NASA
En 1999, la NASA perdió 125 millones de dólares al fallar la misión del Mars Climate Orbiter, una sonda enviada para monitorear el clima de Marte. La causa? Un problema de calidad de datos: los técnicos ingresaron las instrucciones en el sistema métrico imperial, pero la sonda esperaba datos en el sistema métrico estándar. El error provocó que se acercara demasiado a la atmósfera marciana y la presión la desintegró antes de entrar en órbita.
Esta es una situación extrema, pero en ejemplos más bajados a tierra también se ven las consecuencias de la mala calidad de datos:
Dashboards que no se actualizan o muestran datos incorrectos
Modelos de IA que toman decisiones claramente erróneas
Clientes que ven precios mal cargados en un e-commerce
Reportes desactualizados que terminan en decisiones desacertadas
Qué es exactamente la calidad de datos?

La calidad de un dato está definida por el grado en el que cumple con las expectativas del consumidor (la persona o sistema que va a utilizarlo) en función del propósito que ese consumidor quiere cumplir. Es decir: no existe un dato “bueno”, depende de para qué se lo quiera usar.
Vamos con un ejemplo: cuándo un dato de email es “bueno”?
Si una analista de marketing quiere lanzar una campaña por email, necesita que el campo de email esté completo para todos los usuarios. Si falta el dato, la campaña pierde alcance. En este caso, el dato es útil sólo si está presente. Pero si un data scientist usa ese mismo dataset para analizar comportamiento de compra, tal vez el email no sea relevante. La expectativa cambia, y por lo tanto, también la evaluación de calidad.
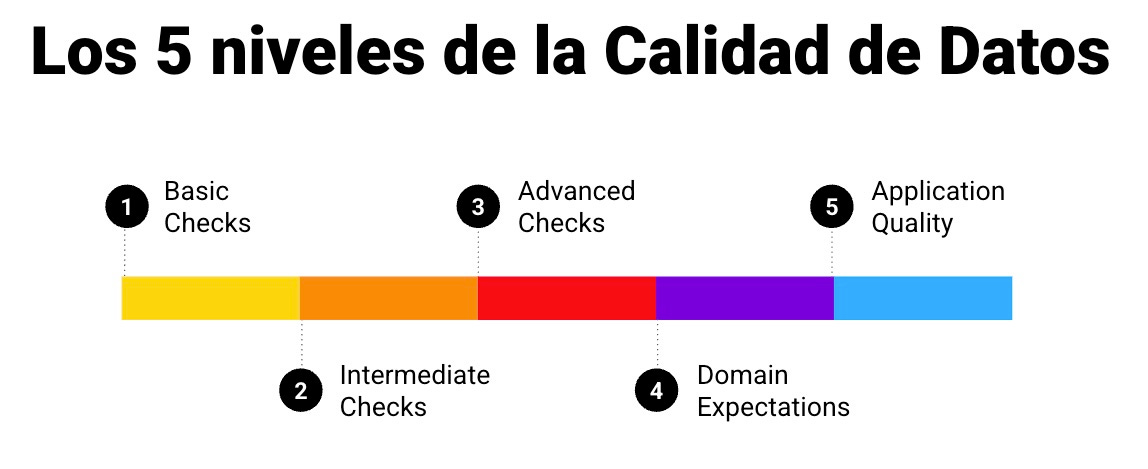
Cinco niveles para entender la calidad de los datos
Para abordar esta complejidad, es útil pensar la calidad de datos en cinco niveles progresivos, que ayudan a organizar las validaciones posibles y priorizar esfuerzos:
Chequeos básicos (nivel 1)
Validaciones intermedias (nivel 2)
Validaciones avanzadas (nivel 3)
Reglas de negocio (nivel 4)
Calidad de aplicación y gobernanza (nivel 5)

En el próximo post te voy a contar en detalle los primeros dos niveles: aquellos que son más simples de implementar pero que ya permiten detectar una gran cantidad de errores. Con herramientas como SQL o librerías open source es posible empezar a mejorar la calidad de datos sin necesidad de grandes plataformas ni arquitecturas complejas.
Nos vemos en el próximo!
Si todavía no lo hiciste podes:
Suscribirte para no perderte nada:
Sumarte a la comunidad de Calidad y Gobierno de Datos que tenemos en Latinoamérica
Seguirme en LinkedIn donde publico más contenido de Data Quality y Data Governance!